머신러닝이란: 일종의sw.
어떠한 입력을 기반으로 결과를 보여주는 것이 explicit 프로그램,
그런데 정확하게 나타내기 어려운 경우가 있다
-> ex.스팸 메일 자동 필터링 같은 경우
-> ex. 구글의 자율 운전 자동차
1959년, 아더가 어떠한 현상에서 자동적으로 배워내게 만들면 어떨까 하는 생각에서 나타난 것이 머신 러닝
-> 프로그램인데 개발자가 일일이 정하는 것이 아니라 프로그램 자체가 어떤 데이터를 보고 학습해서 어떤 것을 배우는 명령을 같는 프로그램
학습을 하기 위해 어떤 데이터가 주어져야 하는데
학습 방법에 따라2가지로 나뉨
1. supervised
: 감독관, label, 정해져 있는 데이터(training set) 을 가지고 학습을 하는 것
: ex 1. image labeling - 고양이, 개(label) 사진을 가지고 구분해 내는 것
: ex 2. email spam - 이메일 가운데 어떤 것이 스팸인지 그냥 햄인지 label
: ex 3. predicting exam score - 내 성적이 얼마나 나올까(이전에 시험을 친 사람이 몇시간 공부했는데 결과가 어떻다 라는 label)
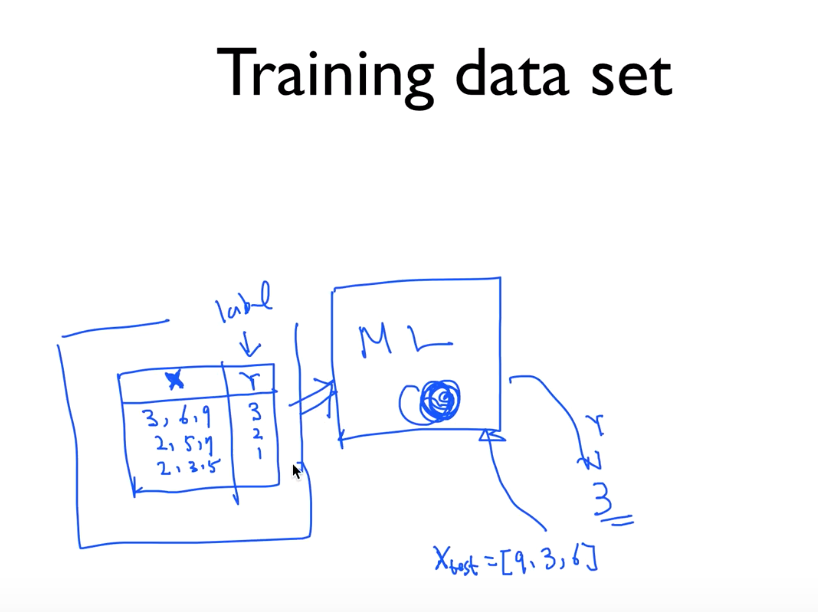
: supervised learning 의 type
1) regression: 0~100 등의 일정 범위(ex. 시험 점수 예측 등)
* regression : 회귀
: 관찰된 연속 형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해내는 분석 방법
: 시간에 따라 변화하는 데이터나 어떤 영향, 가설적 실험, 인과 관계의 모델링 등의 통계적 예측에 이용

2) binary classification: 0/1 , pass/non-pass

3) multi-label classification: 여러 레이블 중 택1 (A,B,C,D and F)

2. insupervised
: 그러나 어떤 경우에는 일일이 label 을 줄 수 없는 경우가 있음
: ex. 구글 뉴스-> 자동적으로 비슷한 뉴스들을 그룹핑
: ex. 비슷한 단어 모으기
출처 : 모두의 딥러닝 https://hunkim.github.io/ml/
'AI & Deep Learning > 이론' 카테고리의 다른 글
| Logistic Classification (Binary) (0) | 2019.04.01 |
|---|---|
| Multi variable linear regression (0) | 2019.04.01 |
| Linear Regression cost 함수 최소화 (0) | 2019.04.01 |
| Linear Regression 의 개념 (0) | 2019.04.01 |
| tensorflow 의 기본 (0) | 2019.04.01 |



